
Puoi avere il sito più bello e funzionale del mondo, ma se non è ben visibile ai tuoi potenziali clienti le tue opportunità di business saranno sprecate.
Pensa all’importanza della posizione strategica di un esercizio commerciale: i clienti che affluiscono, ad esempio, in un bar che si trova in una zona centrale, di continuo passaggio, sono normalmente più numerosi di quelli di un bar posizionato in una piccola via di periferia, in cui non passa mai nessuno.
Per far sì che il tuo sito abbia l’affluenza di traffico che ti aspetti è opportuno che sia ben visibile nei risultati dei motori di ricerca. Da qui l’esigenza di svolgere una SEO Audit, un’ispezione dal punto di vista SEO del sito web volta a migliorarne il posizionamento: un’analisi che dovrebbe affrontare chiunque ha un sito, indipendentemente dagli obiettivi del sito e da quanto tempo questo è online.
Prima di addentrarci nella lista di attività da verificare e implementare durante una SEO Audit, è importante sottolineare che le dinamiche del web e gli algoritmi dei motori di ricerca sono in continua evoluzione e che, di conseguenza, anche le attività di ottimizzazione cambiano nel corso del tempo, soprattutto il peso specifico di ognuna.
Ci addentriamo in una fase in cui Google è sempre più attento alle intenzioni di ricerca degli utenti, anche quelle non esplicite, e soprattutto all’utilità che i siti dimostrano nel soddisfare le esigenze dei navigatori.
Fatta questa premessa, ecco una checklist che può considerarsi una buona base di partenza per una SEO Audit di un sito web.
In questa prima parte dell’articolo vedremo i temi riguardanti Scansione e Indicizzazione, nella seconda parte ci concentreremo su Contenuti, Attività offsite e Linea strategica da seguire.
#1 Scansione e Accessibilità del sito
Google e altri motori di ricerca, per rilevare le pagine e i siti presenti in rete, utilizzano dei piccoli software chiamati in diversi modi (crawler, spider, robot), che scansionano ininterrottamente la rete in cerca di contenuti da indicizzare.
Se i Robots non riescono ad accedere alle pagine del tuo sito, è come se queste risultassero invisibili al motore di ricerca e non comparirebbero nei risultati.
Per assicurarti che i Robots abbiano piena accessibilità al tuo sito e alle sue pagine, verifica:
Robot.txt
Il file robots.txt è un file di testo che fornisce indicazioni ai robot quali sezioni del sito scansionare e quali invece no.
È fondamentale assicurarsi che l’accesso a importanti pagine del sito non sia bloccato a causa di qualche comando presente nel robots.txt.
Viceversa, bisognerebbe segnalare a Google quali sezioni del sito sono inutili da scansionare e conseguentemente indicizzare: pensiamo, ad esempio, all’area riservata o all’area login o al carrello in un ecommerce. Evitare che i robot perdano tempo a effettuare il crawling di queste pagine permette di concentrare il tempo limitato che essi hanno a disposizione per la scansione del nostro sito su pagine di rilievo e valore, ottimizzando cosi il loro sforzo e premiando il ranking del sito.
I comandi base di un robots.txt sono “user agent” per indicare i robots di riferimento e “allow” e “disallow” per indicare quali pagine scansionare o meno.
Nel seguente settaggio di comandi, ad esempio, viene impedito a tutti i robot di scansionare tutte le parti del sito:
User – agent : *
Disallow : /
Il file robots.txt deve essere posizionato nella root del sito web, così da permettere ai robot di avere subito un’indicazione di quali contenuti scansionare. È possibile editare un normale file di testo con estensione txt e caricarlo direttamente tramite ftp oppure attraverso Google Search Console.
Assicurati che sia presente un file robots.txt nelle risorse del tuo sito e che i comandi presenti siano in linea con le tue esigenze. Per verificarlo, digita l’url del tuo sito seguito da /robots.txt (www.sitoweb/robots.txt).
Di seguito un esempio di file robots.txt in cui sono mostrati diversi comandi che indicano a tutti i robot di non procedere con la scansione di alcune parti del sito:
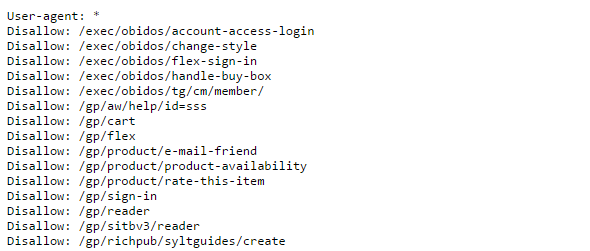
Sitemap
La sitemap è un file con estensione .xml che fornisce ai robot una mappa guida di tutte le url delle pagine del sito in modo da facilitare la loro scansione e ottimizzare il tempo per effettuarla.
Le sitemap vengono costruite normalmente seguendo un ordine gerarchico delle url e contengono indicazioni sulla loro priorità e sulla loro frequenza di aggiornamento, in modo che i crawler abbiamo indicazione su quali siano le più importanti e ogni quanto ripassare per aggiornarne i contenuti.
Per creare una sitemap ci si può avvalere dell’aiuto di un programmatore o utilizzare software di generazione automatica e plugin, come, ad esempio, Google XML Sitemap per siti in WordPress. Una volta creata la sitemap, è opportuno sottoporla all’attenzione di Google tramite il pannello di Search Console.
Le sitemap sono utili per siti con numerose pagine. Per un sito con 5 o 6 pagine non è fondamentale inserirle.
Di seguito parte della sitemap di Zalando:

Status Code – Errori 4xx o 5xx
Per assicurarsi che i robot riescano ad avere accesso ai contenuti è necessario verificare che le url del tuo sito non restituiscano errori di status code come 4xx o 5xx.
Errori di questo tipo indicano che la scansione da parte dei robot risulta bloccata (il percorso verso l’indicizzazione di queste pagine s’interrompe). Quando, ad esempio, la pagina o la sezione di un sito viene “spenta”, il classico status code di errore che viene restituito è il 404: il robot non riesce più a individuare la risorsa (il contenuto) presente a quell’indirizzo. Per evitare l’interrompersi dell’indicizzazione del contenuto e dell’esperienza utente, è necessario impostare un redirect, cioè reindirizzare robot e utenti verso un’altra pagina, che verrà visualizzata al posto di quella “spenta”.
Effettua una scansione del sito utilizzando un tool come Screaming Frog per verificare quali pagine restituiscono errori di status code. Otterrai in automatico una scansione di tutte le pagine con relativa indicazione degli errori da risolvere.
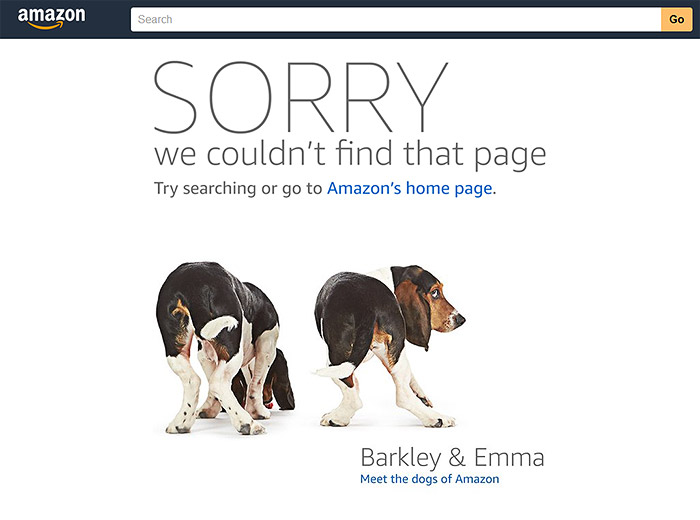
Errore ancora più serio è il 5xx, che indica una mancata risposta del server.
Performance
Non solo gli utenti ma anche i robot non amano siti che impiegano troppi secondi per caricarsi. Le pagine di un sito che si caricano velocemente saranno scansionate e indicizzate in maniera migliore e più consistente. Il tempo che un robot può dedicare all’indicizzazione di un sito è infatti limitato e fare in modo che sia allocato nel modo più efficiente possibile risulta un fattore premiante.
Per valutare la velocità di caricamento di un sito puoi utilizzare diversi strumenti, tra cui Google Page Speed o Pingdom Full Page Test, che, oltre a fornire un’indicazione sui tempi di caricamento, danno brevi e utili suggerimenti su cosa fare per migliorarlo, o lo stesso Screaming Frog che restituisce i tempi di caricamento di ciascuna pagina.
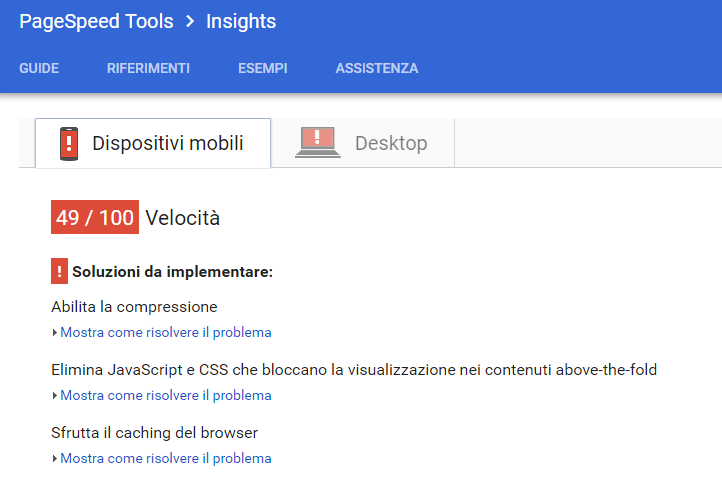
#2 Indicizzazione del sito
Una volta controllato che le pagine del tuo sito sono effettivamente accessibili e scansionate dai robot, è giunto il momento di verificarne l’effettiva indicizzazione, cioè la presenza e il posizionamento nella pagina dei risultati di ricerca di Google o di altri motori di ricerca. L’attività di indicizzazione, cioè la creazione di un indice di pagine, è in realtà effettuata da un software chiamato robot index, diverso dal crawler di scansionamento. È quindi doveroso considerarla in tutto e per tutto un’attività distinta dalla scansione.
Nell’affrontare questo step, durante una SEO Audit fai attenzione ai seguenti aspetti.
Verifica
Per verificare l’avvenuta indicizzazione delle pagine possiamo innanzitutto farci aiutare dal comando Site Search.
È possibile utilizzare questo comando per scoprire quali sono state le pagine indicizzate del nostro sito internet. Digita su Google site: seguito dal dominio del tuo sito: otterrai l’elenco di tutte le pagine che sono indicizzate. Potrai in questo modo fare un confronto tra il numero di pagine del tuo sito e quelle effettivamente restituite dai risultati del motore di ricerca.
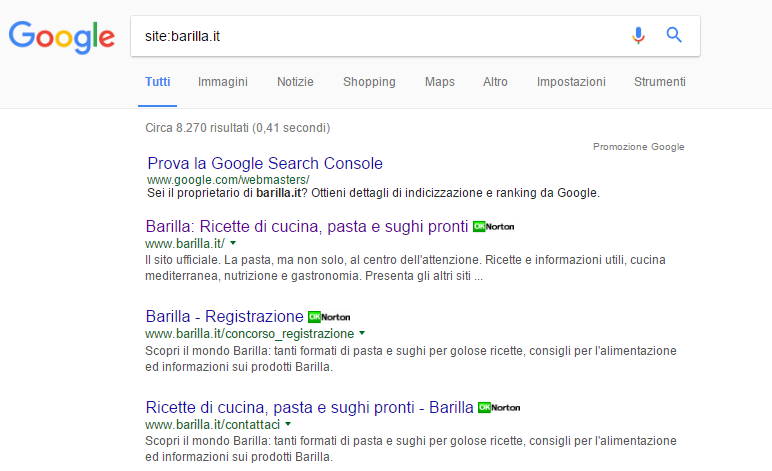
Se le pagine indicizzate e quelle del tuo sito sono equivalenti, è un ottimo segnale. Significa che i robot del motore di ricerca stanno scansionando e indicizzando tutti i contenuti.
Se invece le pagine indicizzate sono in numero inferiore, significa che diverse pagine non sono indicizzate. Il problema potrebbe essere la mancata scansione delle pagine, che dovresti aver identificato effettuando la scansione del sito tramite Screaming Frog.
Nel caso in cui il numero di pagine indicizzate sia nettamente inferiore, il problema potrebbe essere la penalizzazione del sito.
Penalizzazione
È piuttosto evidente accorgersi di una penalizzazione: se si effettuano ricerche brand, non compaiono tra i risultati le pagine del proprio sito. Le pagine vengono completamente deindicizzate e non rispondono al comando site:, a questo punto, di solito si riceve un messaggio da parte del motore di ricerca che informa della penalizzazione. Nel caso di una penalizzazione da parte di Google, il messaggio viene inviato tramite il pannello di Search Console.
Un caso analogo, in cui potrebbe registrarsi una consistente perdita di traffico, si ha quando viene introdotto un aggiornamento dell’algoritmo del motore di ricerca. In questo caso non si tratta di una vera e propria penalizzazione, ma bisogna affrontare una situazione simile: si dovranno capire e reinterpretare le nuove logiche di indicizzazione dell’algoritmo e andare ad apportare, di conseguenza, i cambiamenti necessari sul proprio sito.
Se di penalizzazione vera e propria si tratta, i passaggi da seguire sono due.
– Capire le cause della penalizzazione. Se si riceve una notifica formale da parte di Google i motivi della penalizzazione vengono spiegati.
Dopo aver identificato quali sono le cause che hanno portato alla penalizzazione, si dovranno sistemare uno per uno gli aspetti del sito legati a ciascuna di esse. Per facilitare le operazioni, è utile rivolgersi alle community SEO, come ad esempio quella di Moz, attiva e ricca di informazioni, in cui è possibile recuperare suggerimenti su come e cosa fare in caso di dubbi.
– Richiedere la riconsiderazione del sito. Una volta sistemati i problemi, è necessario richiedere la riconsiderazione da parte dei motori di ricerca da cui si è stati penalizzati.
Se ti interessa approfondire l’argomento, ecco un interessante articolo su alcuni tra gli esempi di penalizzazione più famosi, pubblicato da Studio Samo.
Standard Html Markup – Attributi rel
Gli attributi rel sono elementi di codice html che forniscono informazioni ai robot, utili per favorire una buona e corretta indicizzazione delle pagine. In particolare gli attributi rel forniscono indicazioni sul tipo di relazione che si instaura tra la pagina considerata e quelle a essa linkate. I più importanti sono tre.
– Rel Prev/Next: utili per risolvere il problema della cosiddetta paginazione. Nel caso i contenuti appartenenti a una stessa serie si distribuiscano su più pagine, ad esempio l’elenco di prodotti in una categoria ecommerce o le pagine del testo di un articolo, la configurazione in diverse pagine potrebbe portare dei problemi in termini di indicizzazione.
I robot potrebbero, ad esempio, non capire qual è la prima e più rilevante pagina della sequenza e indicizzare principalmente una delle pagine secondarie. Utilizzare gli attributi rel prev e next permette di fornire indicazioni su quale sia la sequenza delle pagine e portare i robot a indicizzare la prima pagina della sequenza, normalmente la più rilevante.
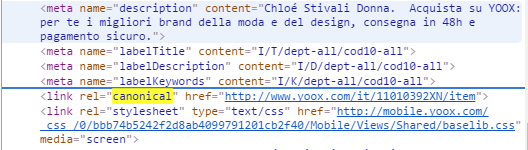
– Rel Canonical: indicano con chiarezza ai robot, in caso di pagine pressoché identiche, quale pagina è da considerasi come canonica e quindi da indicizzare. Sono importanti per prevenire il classico problema dell’indicizzazione di contenuti duplicati (penalizzati in termini di ranking da Google), tipico, ad esempio, delle pagine prodotto con contenuti simili negli ecommerce.
– Rel nofollow: permette di dare indicazione ai robot di quali link non seguire all’interno di una pagina e quindi non scansionare e indicizzare. Nell’ottica di utilizzare al meglio il budget di scansione dei robot, può essere utile prevenire i crawler dal seguire, ad esempio, pagine poco rilevanti da indicizzare, come, ad esempio, quelle di registrazione o log in.
Per implementare i rel attributes è possibile chiedere il supporto di un programmatore o utilizzare alcuni plugin. I cms più diffusi permettono di gestire facilmente questi attributi tramite plugin, senza agire direttamente sul codice sorgente.
Ecco come Yoox usa l’attributo rel canonical all’interno del codice sorgente di una scheda prodotto per evitare la duplicazione di contenuti e favorire l’indicizzazione delle pagine:
Questi sono i principali accorgimenti per quanto riguarda scansione e indicizzazione, i primi aspetti su cui dovresti porre l’attenzione quando svolgi attività volte a migliorare il posizionamento di un un sito web.
Nella seconda parte dell’articolo completeremo la checklist affrontando il tema delle attività on site, dei contenuti e della strategia, con particolare attenzione a quelli che sono gli aspetti a cui Google sta dando maggior rilievo per determinare il ranking nei propri risultati di ricerca.
Rimanete sintonizzati su Webhouse!


{kind=link}